

SEO Spider traps, or as they are commonly known, crawler traps are one of the most unfortunate technical SEO problems that can happen to your website. They make it hard and sometimes impossible for the crawlers to explore your website expeditiously. These crawler traps constitute a structural problem in a set of web pages, causing search engine spiders to make an infinite number requests for irrelevant urls. In turn, this affects the indexing process and, ultimately, your ranking. In this article, we’ll discuss spider SEO traps, their causes, how to identify and prevent them, and possible solutions.
What are spider SEO traps?
Spider traps is a term used to describe a technical issue with your website structure. These traps yield unending URLs, which make it impossible for the spider to crawl. Consequently, the spider gets stuck on these traps and fails to reach the good parts of your website. The search engine has a defined number of pages it’s willing to explore when crawling a site, which is known as a crawl budget. Since crawl traps lead to pages that have no SEO relevance, search engine bots fail to reach the essential pages hence resulting in wasted crawl budget.
Time and budget spent developing SEO is completely wasted if search engines never crawl the desired page, and the sites ranking never benefits from optimization.
Crawler traps can also cause duplicate content issues. Large numbers of low quality pages are indexable and accessible to viewers after encountering a crawler trap. By solving for traps, sites can also resolve their issues with duplicate content on search engines.
How to identify a spider trap
- Use a crawler-based tool like Xenu’s Link Sleuth or Screaming Frog to check if a site has a spider trap.
- Start a crawl of the site and let it run for a while. If the crawl eventually finishes, then there is no spider trap.
- If your website is not very large and the crawl runs for a very long time, it is possible, your website is facing spider trap issues.
- Export a list of URLs and your worst fears are confirmed if:
- There is a pattern where all of the new URLs look suspiciously similar to each other.
- To confirm your suspicions, plug some of these URLs in the web browser. If all the URLs return the same page, then your website definitely has a spider trap.
How to identify different types of SEO spider traps and their causes
There’re four common crawl traps that require different methods of identification. These include;
- Never-ending URL
- Mix and match trap
- Session ID trap
- Subdomain redirect trap
- Keyword search crawl trap
- Calendar trap
Below is a guide on how to identify and fix each of these spider crawls
1. Never Ending URL
A never-ending spider traps SEO occurs when an infinite number of URLs direct to the same page with duplicate content. The trap results from poorly written relative URL or poorly structured server-side URL rewrite rules.
Example:
http://abcwebsite.com/size11php
http://abcwebsite.com/1234/size11php
http://abcwebsite.com/1234/1234/size11php
http://abcwebsite.com/1234/1234/1234/size11php
http://abcwebsite.com/1234/1234/1234/1234/size11php
http://abcwebsite.com/1234/1234/1234/1234/1234/size11php
http://abcwebsite.com/1234/1234/1234/1234/1234/1234/size11php
http:// abcwebsite.com/1234/1234/1234/1234/1234/1234/1234/size11php…
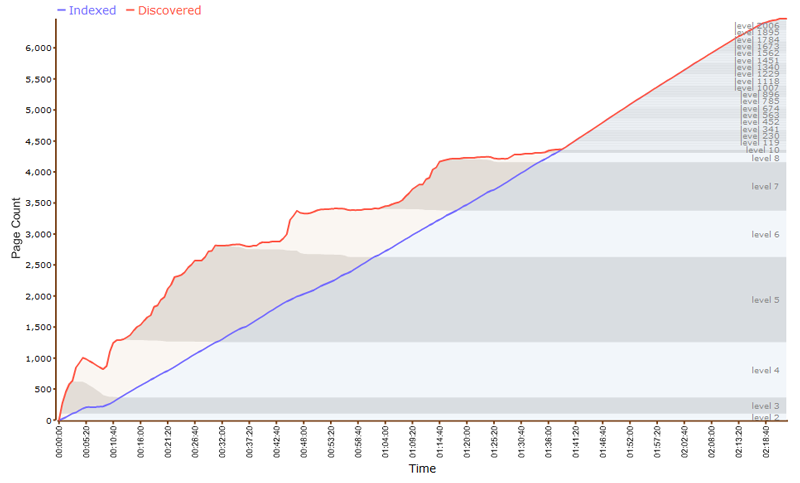
Identifying and Fixing Never-ending URL Traps
You can identify these traps if any of the following happens when using a crawler-based tool;
- The URL keeps getting longer and longer without stopping
- The crawl runs smoothly until it reaches the junk pages of your site
- If at some point the crawled URLs start taking a strange form which is an extension of the crawled pages
You can fix this spider trap by using a crawler tool and setting it to sort the URLs by their length. Pick the longest URL, and you’ll locate the root problem.
2. Mix and Match Trap
This issue normally occurs in e-Commerce portals that provide users the option to place multiple filters for selecting the right product.
How to Identify and Fix Mix and Match Crawl Trap
Various filters for products per page can create issues for a crawler.
Some tips to fix this issue:
- Offer fewer filter options
- Implement mix and match filtering in Javascript
- Judicious use of robots.txt to block pages with too many or too few filters
3. Session ID Crawl Trap
This is another spider crawl trap that usually plagues e-Commerce portals. The search bots end up crawling pages with similar content, with varying session IDs.
How to Identify and Fix Session ID Crawl Trap
While assessing your site crawl, do you find session IDs like
- Jsessionid
- Sid
- Affid
or anything similar within the URLs strings, with the same IDs reoccurring?
This could mean your website is facing a session ID crawl trap.
4. Subdomain Redirect Trap
The trap happens when your page is running on a secure connection, but every page on the unsecured site is being directed to your secured homepage. The trap makes it hard for Google bots to redirect the old and unsecured pages. You can prevent this trap by rechecking and confirming that your site has the correct redirect after every server update, maintenance, or CMS update.
Example:
http://abcwebsite.com/size11 redirects to https://abcwebsite.com/
Ideally it should redirect to https://abcwebsite.com/size11 on the secure site
How to Fix Subdomain Redirect Trap
The spider traps SEO occurs due to CMS/webserver misconfiguration. Rectify it by editing your webserver configuration. Alternatively, you can edit the CMS and add the request URL redirect string.
5. Keyword Search Crawl Trap
The search function is not meant to be crawled or indexed by the search engine. Unfortunately, many website developers tend to forget this. When this happens to your website, it becomes easy for someone with malicious intentions to add indexable content to your site even without being logged on.
How to Identify and Fix Keyword Search Crawl Trap
Perform a search audit and review whether the search function generates unique URLs, or there are common characters or phrases in the URL. If you detect any problems, fix them by;
- Get the site re-crawled by adding no index no follow metadata to the search results to remove some of the search results from the search engine
- Then block the removed paged using robots.txt
6. Calendar Trap
Calendar traps occur when your calendar plugin legitimately generates many URLs into the future. The problem with this trap is that it creates countless empty pages, which the search engine will have to crawl when exploring your website.
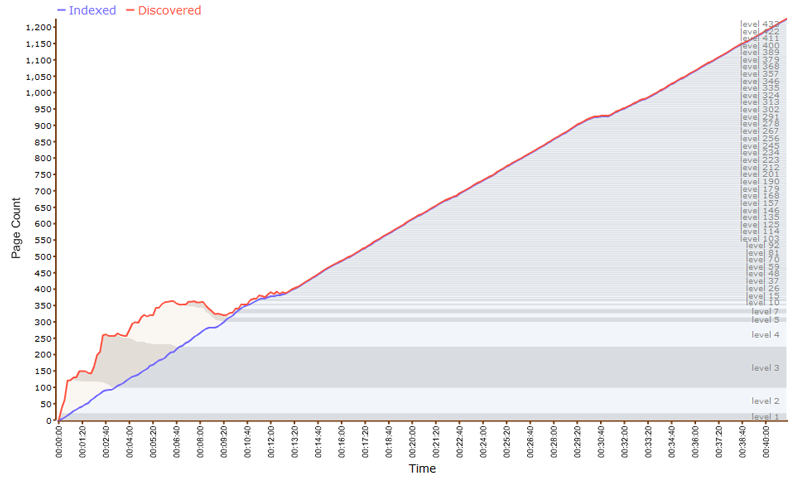
Identifying and Fixing Time Trap
Although Google will eventually detect and remove irrelevant calendars on your site, you can also discover the trap manually.
If the site has a calendar page, go to it and click the ‘next year’ (or ‘next month’) button repeatedly. If you can eventually go numerous months/years, then the site has a calendar trap.
Input the command (site:www.example.com/calendar) to view the indexed pages of your calendar. Manually inspect your calendar plugin settings and see whether there’re measures to limit the number of months into the future. If there’s no protection, then you’ll have to block the calendar pages by;
- Going to the robots.txt
- Setting a reasonable number of months into the future
- Blocking the calendar pages
How Spider Traps Impact Your SEO
Although resulting from different technical and non-technical issues of your website, spider traps have a common consequence on your website; they make it hard for crawlers to explore your site. Consequently, this decreases your search engine visibility, which in turn affects your ranking. Other negative impacts include;
- Decrease in the quality of your ranking by Google algorithms
- Affect the ranking of the original page in cases where the spider traps cause near-duplicate pages
- Waste of crawl budget as search bots waste time loading irrelevant near-duplicate pages
The Final Word
Theoretically, a “polite” spider, who only requests documents from a host once every few seconds, and alternates its requests between hosts, is far less likely to get trapped in a crawler. Sites can also set up robot.txt to instruct bots to avoid the crawler trap once they’re identified, but this isn’t a guarantee a crawler won’t be affected. Taking the time to identify to fix crawler traps supports other measures taken to optimize SEO relevance and site ranking.
- Save, and preserve, raw web server logs
- Conduct technical SEO audits regularly.
- Add parameters as fragments, as search engine crawlers ignore URL fragments.
- Regularly run your own crawls, and make sure the correct pages are the ones crawled.
- Check a variety of user-agents. You may not have the clearest picture of your site if you’re only viewing it through one user-agent. Bots may be caught in loops of canonical tags, that visitors don’t encounter because they selectively click links.
Use this guide to identify, remove, and prevent spider traps. They all occur due to various reasons, but they all have a collective impact, deter the success of your website.


